

Data from 89% of healthcare organisations have been stolen in the past two years due to cyberattacks. As many as 81% of the cybersecurity-related incidents in healthcare result from employees’ negligence. Patient health records can be sold on the black market for as much as USD 363, which is higher than a cost of any information from other industries [source: PurpleSec]. These statistics sound rather serious, but this is just the tip of the iceberg. The importance of IT systems security increases every year. The number of cyberattacks grows constantly and new types of malware continue to be created.
Although cybersecurity applies to all web services available on the public network (and beyond it), this issue becomes much more complicated in the case of systems using machine learning. Due to being strongly dependent on input data, the models for such software are exposed to specific types of attacks.
The most popular cyberattacks are data poisoning, adversarial attack and inversion by surrogate model. Naturally, there are many other possible threats, with more advanced and effective means of cyberattack being developed over time. In the following part of this article, I will try to characterise the abovementioned methods and present the means for proactive protection of a ML system against potential risks.
Data Poisoning
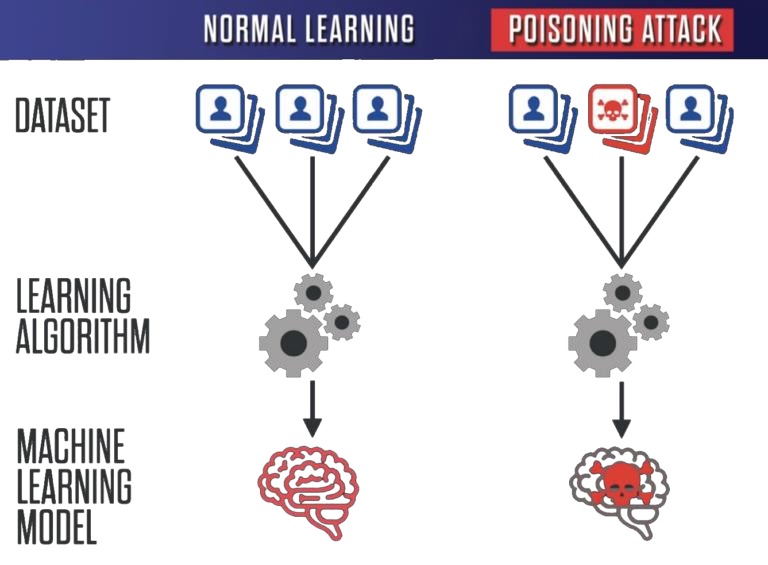
Image 1: Graphical representation of data poisoning [source: Attacking Artificial Intelligence].
This cyberattack involves the “poisoning” of a dataset used to train a machine learning model. Such modification may be intended to effectively degrade the quality of produced predictions. Specific variant of this attack is called label flipping. It can lead to deliberate targeting of inference results, e.g. teaching a model to accept adverse credit applications.
However, in order to poison the data, an attacker would need to gain access to an entire training set or some part of it. Nevertheless, it can be done, for example, using equipment of an employee or a subcontractor of a given company who has access to a significant number of repositories.
This attack may also involve adding seemingly harmless columns to a training set. These columns could be then used by an attacker to deliberately trigger a specific mechanism in a model, which leads to obtaining intended predictions.
Adversarial attack
This method is based on an attacker attempting, through trial and error, to create small differences in input data in order to obtain an unexpected prediction. A perfect example is the manipulation of a neural network used for image classification. Even by modifying only one pixel, an attacker is able to drastically alter the results generated by a system.
Nevertheless, this kind of cyberattack can also target other prediction systems based either on natural language or solely on scalar data.

Image 2: Graphical representation of the results obtained due to the attack [source: One Pixel Attack for Fooling Deep Neural Networks].
Inversion by surrogate model
This method involves the extraction of confidential information regarding a model for a given ML system. For this purpose, an attacker needs to be able to generate a large number of predictions using an API, website or app, based on properly prepared input data.
On the basis of the results obtained and the input used, it is possible to train a new model which resembles the one utilised in said system. If the number of received predictions is large enough, the attacker is able to train an almost identical replica.
A model crafted this way can then serve as a basis for exploring potential weaknesses of the system, allowing for intentional generation of predictions (as in the case of adversarial attack).
How to effectively defend yourself?
Although there is no set solution for a fully secure ML system, there are ways to protect it from the cyberattack methods presented above. The first line of protection against many attacks are the monitoring processes, which can detect potential threats and provide alerts. A cyclical analysis of data processed by the system is able to report possible anomalies and unusual patterns.
Except for monitoring given model, one can also focus on ensuring the security during its implementation, for example with Reject On Negative Impact (RONI) protection. This technique involves determining the empirical effect of each training sample and eliminating points which have a negative impact on the inference accuracy from the set.
The use of RONI may result in creation of a model which is much more resilient to potential attacks. In addition, it might be beneficial to introduce safety measures that are used in standard internet apps:
- requiring a two-factor authentication,
- limiting a large number of demands from a single client,
- monitoring network traffic.
The issue covered in this article is the final part of a series of texts regarding the role of MLOps in business. I believe that with this and previous texts I have presented a lot of useful information from the field of ML systems creation. I hope that the presented knowledge was interesting and will allow for further development and implementation of even better software. Thank you!
Sources:
- https://purplesec.us/resources/cyber-security-statistics/
- https://www.excella.com/insights/ml-model-security-preventing-the-6-most-common-attacks
- https://www.h2o.ai/blog/can-your-machine-learning-model-be-hacked/
- https://www.oreilly.com/content/proposals-for-model-vulnerability-and-security/
- https://people.eecs.berkeley.edu/~adj/publications/paper-files/SecML-MLJ2010.pdf
- https://www.belfercenter.org/sites/default/files/2019-08/AttackingAI/AttackingAI.pdf













